Pyntacle Quickstart Guide
Pyntacle version 1.3.2
Table of Contents¶
- Introduction
- Setting Pyntacle for the first use
- Dataset description
- Command-line guide
- Pyntacle APIs quick guide
- Import a network using Pyntacle
Octopus: A convenient wrapper of Pyntacle methodsOctopus: Computing key-player metrics for a given set of nodesOctopus: Greedy-optimization searchOctopus: Brute-force search- Exporting the
igraph.Graphobject - Key-player search without
Octopus: Brute-force search (case example)
Introduction ¶
This brief tutorial will show how to use Pyntacle from the command-line or its API interface to find relevant groups of nodes (also called here the kp-set) in a network using the fragmentation and reachability key-player metrics.
Fragmentation is the structural effect of removing nodes from a network. Reachability is the property of nodes to reach their direct or indirect neighbors in a network with a few connections. Although we will provide here a brief explanation of these concepts, we recommend reading the introduction to group centrality section.
All data used in this tutorial are available here for download.
Setting Pyntacle for the first use ¶
After installing Pyntacle as described here and activating the Pyntacle's conda environment by typing
conda activate pyntacle_env
Note: pyntacle_env is just a naming convention
You can then check the Pyntacle version by typing:
pyntacle --version
Installation is correct if the following command ends succesfully:
import pyntacle
Otherwise, contact us and send us a description of the error, along with all the necessary information to reproduce the error.
Dataset description ¶
The toy dataset used here is the network of advice-seeking ties among global consulting companies (also called as the AdvSeek network in this tutorial). This network was already used in the original paper by Stephen P. Borgatti, in which the key-player metrics are introduced, Identifying sets of key players in a social network.
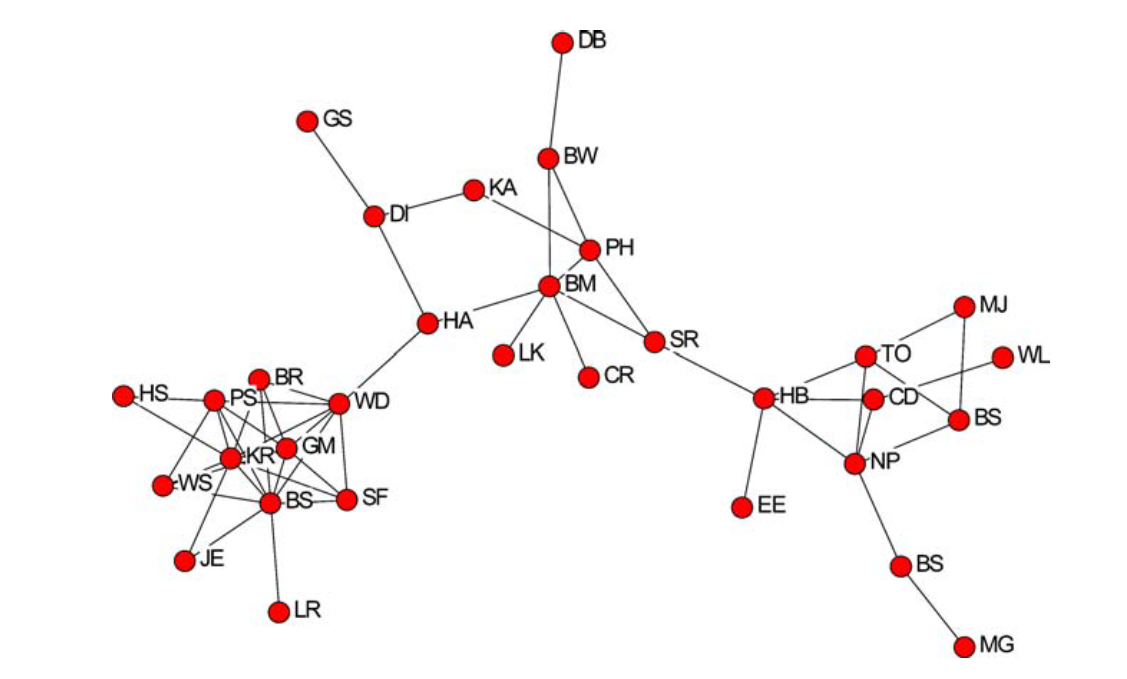
We made this network available here as an adjacency matrix (cf. the supported file formats). Nodes in the network are labeled with the initials of the consultants. Since some of the consultants share the same initials, we appended progressive numbers to their initials (e.g. BS, BS2, BS3, etc) to be compliant with the Pyntacle Minimum Requirements. Edges represent relationships among consultants.
Command-line guide ¶
Testing the Pyntacle command-line ¶
To check that Pyntacle is properly installed and working, a set of unit tests can be run by typing:
pyntacle test
Several tests will be launched. If succesfull, this command will result in the following message:
Ran 27 tests in 21.002s
OK
Otherwise, please contact us specifying your operative system, its version, how you installed Pyntacle and the output of your tests in a text file. You can redirect the output of the tests this way:
pyntacle test >> testlog.txt 2>&1
Once verified the correct installation of Pyntacle, you can replicate some of the results of Borgatti’s original article in two steps.
kp-info: Computing the key-player metrics for a given set of nodes ¶
First, the Pyntacle kp-info function will be used to measure the dF fragmentation index for a specific set of nodes of the network. Borgatti measured dF for the pair {HB, WD} and obtained a value of 0.817. We recall here that dF ranges from 0 to 1, where 0 means maximum connectedness (i.e., the network is a clique) and 1 means maximum disconnection (all nodes are isolates). This result can be replicated by typing:
pyntacle keyplayer kp-info -i AdvSeek.adjm -t dF --nodes HB,WD
This command returns the following output (we report the final summary only for the sake of readability):
****************************************** RUN SUMMARY *******************************************
Removing node set
(HB, WD)
gives a dF value of 0.81716
Starting graph dF was 0.64939
****************************************************************************************************
The resulting fragmentation can be better assessed comparing the dF of the original network (before node removal) with that calculated after the node removal. For this reason, kp-info returns also the dF value of the original network.
Results of kp-info can be saved in several file formats (default is tab-separated).
Note: you can specify a custom target directory using the --directory/-d argument
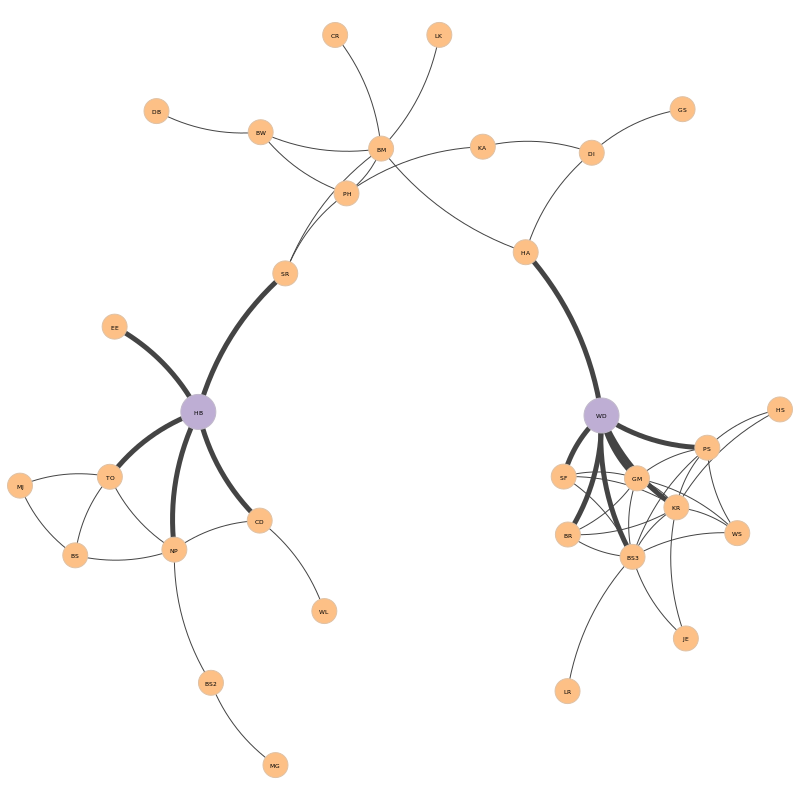
The representation of the AdvSeek network follows, with the removed nodes represented in purple. (Thicker edges around the kp-set highlight the {HB, WD} neighborhood)
kp-finder: Greedy-optimization search ¶
The set of nodes of a particular size (k) that maximally fragment a network or that reach the highest number of other nodes can be obtained using the greedy-optimization search algorithm. It will search for a suboptimal set of nodes of size k for a selected key-player metrics. Starting from a random set of nodes and then swapping nodes with others outside the set until the selected key-player metrics cannot be improved, one dramatically reduces the number of operations at the cost of suboptimal solutions. This algorithm is particularly useful when dealing with large networks.
The key-player metric chosen in this tutorial is the m-reach, which is a measure of reachability. It aims at counting the number of nodes reached by a vertex set of size k in m steps or less. In Borgatti’s paper, the m-reach metric is calculated on the AdvSeek network for two different k sets and setting m to 1.
| k | Nodes reached | % of network reached | kp-set |
|---|---|---|---|
| 2 | 15 | 53 | {BM, BS3} |
| 3 | 20 | 72 | {BM, BS3, NP} |
Note: The node BS is here called BS3 as there are 3 synonymous nodes in the original graph
To reproduce this result, type:
pyntacle keyplayer kp-finder -i AdvSeek.adjm -k 2 -m 1 -t mreach
kp-finder enables the use of the greedy-optimization search algorithm by default. This behaviour can be changed using the -I/--implementation argument and setting the brute-force (See the brute-force section) or sgd (stochastic-gradient descent) options.
Pyntacle will output (only the run summary is reported):
****************************************** RUN SUMMARY *******************************************
Size of the node set: 2
Key-player set of size 2 for m-reach, using at most 1 step, is:
(BS3, BM)
with value 15 on 32 (number of nodes reached on the total number of nodes)
The total percentage of nodes, which includes the kp-set, is 53.12%
****************************************************************************************************
Note: We report the number of nodes reached by the kp-set (m-reach) and the percentage of reached nodes, which includes the kp-set (as from Borgatti’s paper).
Results are stored in a txt file in the current working directory.
Similarly, the optimal set of size 3 can be sought typing:
pyntacle keyplayer kp-finder -i AdvSeek.adjm -k 3 -m 1 -t mreach
This will produce the following output:
****************************************** RUN SUMMARY *******************************************
Size of the node set: 3
Key-player set of size 3 for m-reach, using at most 1 step, is:
(KR, BM, NP)
with value 20 on 32 (number of nodes reached on the total number of nodes)
The total percentage of nodes, which includes the kp-set, is 71.88%
****************************************************************************************************
The {KR, BM, NP} kp-set is not the one reported by Borgatti {BM, BS3, NP}, despite their scores being identical. This means that this network holds more kp-sets of size 3 with equal fragmentation scores.
A way of getting all these sets would be to run the greedy-optimization search algorithm several times. But this will not guarantee to capture all existing kp-sets. Another, exact, way would be to switch to the Brute-force search algorithm, as we will discuss in the next section.
kp-finder: Brute-force search ¶
Contrary to the greedy-optimization search algorithm, the brute-force search algorithm seeks and finds the best solutions at the price of high demand of computing resources and running times. This task requires
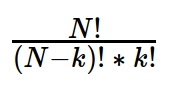 operations, where N is the size of the graph.
operations, where N is the size of the graph.
However, it was implemented to calculate the desired metrics for all the combinations of size k of nodes, in parallel on multiple processors, if available. It can be enabled by setting the -I/--implementation parameter with the brute-force keyword. By default, Pyntacle will use 1 CPU only. However, this can be tuned by the -O/--nprocs parameter.
Let's consider again the AdvSeek network and the case discussed in the previous chapter. The greedy-optimization search did not replicate the Borgatti's findings on the AdvSeek network. Searching again the best kp-sets of size 3 with the brute-force search algorithm:
pyntacle keyplayer kp-finder -i AdvSeek.adjm -k 3 -m 1 -t mreach -I brute-force
****************************************** RUN SUMMARY *******************************************
Size of the node set: 3
Key player sets of size 3 for m-reach, using at most 1 step, are:
(KR, BM, NP)
(BS3, BM, NP)
with value 20 on 32 (number of nodes reached on the total number of nodes)
The total percentage of nodes, which include the kp-set, is 71.88%
****************************************************************************************************
The two best solutions were finally found. This concludes the quick start guide of Pyntacle via command-line. The same problems will be tackled using the Pyntacle's API interface in two ways: using the Octopus wrapper and by directly using the Pyntacle methods for kp-search.
Pyntacle library guide ¶
The APIs are designed for intermediate-to-expert Python users, with a basic knowledge of object-oriented programming and some experience with the igraph package. If you are not acquainted with igraph basics, we recommend reading its official Python tutorial.
Pyntacle is built around igraph and performs its calculations on instances of igraph.Graph objects. Pyntacle provides several tools for importing/exporting from/to igraph.Graph objects and to/from several textual network file formats. We refer to the File Formats Specifications page for more details on this regard. Moreover, we recommend reading the Minimum Network Requirements.
Importing a network using Pyntacle ¶
Networks can be imported from file via the PyntacleImporter class of the io_stream module. This class contains a series of handy methods to parse and store an input graph into an igraph.Graph object and initialize all the Pyntacle reserved attributes (see the Minimum Network Requirements section).
Considering again the AdvSeek network, which is available as an adjacency matrix (AdvSeek.adjm), it is imported with the following command:
from pyntacle.io_stream.importer import PyntacleImporter
adv = PyntacleImporter.AdjacencyMatrix("AdvSeek.adjm")
The imported adv object is of type igraph
type(adv)
The adv object can thus be inspected by means of standard igraph methods:
adv.summary()
Octopus: A convenient wrapper of Pyntacle methods ¶
Octopus' methods are included in the Octopus class of the tools module. This is the list of all available Octopus methods:
from tools.octopus import Octopus
dir(Octopus)
When calling an Octopus function, Octopus will execute the corresponding Pyntacle function, will assign a new attribute to the target graph and will return the result of the called function. For example, let us suppose one wants to compute the average degree of the AdvSeek network.
Octopus.average_degree(adv)
This function will trigger the computation of the average degree, will create an average_degree attribute for the graph adv and will set the result (3.4375 for the AdvSeek Network) to it:
adv.attributes()
adv["average_degree"]
Octopus: Compute key-player metrics for a given set of nodes ¶
With the aim to reproduce Borgatti's results regarding the network fragmentation on the AdvSeek network, as already discussed in the Command-line section, we will use Octopus.
Octopus.kp_dF(adv, nodes=["HB", "WD"])
where nodes is a list of names of the nodes belonging to the kp-set.
Octopus will add a new attribute, dF_info, to the graph adv. This attribute is actually a dictionary, where each item is a key-value pair made by a (sorted) tuple of nodes (the kp-set) and the corresponding dF value.
adv.attributes()
and
adv["dF_info"]
dF is a relative metrics, in the sense that the effect of removing a set can be appreciated if compared with the fragmentation level of the original network. The initial dF value of a network can be computed by using the dF method:
Octopus.dF(adv)
The initial dF is stored in the corresponding dF attribute
adv["dF"]
Now, we can conclude that removing HB and WD will result in a fragmentation increase of 17%.
Octopus: Greedy-optimization search ¶
The previous greedy-optimization search method, which was performed by the kp-finder command line command, can be replicated calling the GO_mreach method.
Octopus.GO_mreach(adv,k=2, m=1)
Like in the previous section, Octopus adds an attribute to the graph that stores a dictionary of node names (kp-set) and centrality measures. In this example, the attribute will be called mreach_1_greedy, since the centrality metrics is the m-reach with m=1 argument and obtained with a run of the greedy-optimization search algorithm.
adv.attributes()
The name of the attribute says that the m-reach metric with m = 1 was computed with the greedy-optimization algorithm. This will ensure that all the following greedy-optimization searches for m-reach of distance 1 will be stored in this variable, keeping tracks of all the runs.
As before, we can obtain the key-values:
adv["mreach_1_greedy"]
Octopus: Brute-force search ¶
Finally, the brute-force search method performed using the command-line can be replicated with Octopus using $5$ CPU cores.
Octopus.BF_mreach(adv, k=3, m=1, nprocs=5)
Again, a new attribute storing the results is added to the adv graph. This attribute is stored with the name mreach_1_bruteforce. It will contain a tuple of $3$ elements storing the node names as key and the corresponding m-reach values.
adv["mreach_1_bruteforce"]
Exporting the igraph.Graph object ¶
Any igraph.Graph object can be saved to text or binary files (we refer again to the File Formats Specifications page). Additionally, graphs can be exported with all their attributes. The export utilities are implemented in the PyntacleExporter class of the io_stream module.
Let us export the adv network to a binary file.
from pyntacle.io_stream.exporter import PyntacleExporter
PyntacleExporter.Binary(adv, "AdvSeek.graph")
This will create a file named advseek.graph in the current directory.
Key-player search without Octopus: Brute-force search ¶
The same functions performed with Octopus can also be performed using the Pyntacle's APIs (algorithms and tools modules). These methods rely on an array of enumerators by which specifying:
- the key-player metrics to be calculated;
- the computing modes for some of the Pyntacle’s methods (i.e., serial, parallel CPU, GPU);
These enumerators are implemented in the tools module and can be imported as:
from tools.enums import KpposEnum #this enumerator stores all the reachability metrics
from tools.enums import CmodeEnum #this one handles all the computing modes
KpposEnum currently includes two reachability metrics: m-reach and dR.
dir(KpposEnum)
CmodeEnum contains four values: auto, igraph, cpu and gpu; auto is the default choice and commands Pyntacle to choose the best computing mode, according to the specific features of the graph is working on. The igraph option is chosen to run the serial versions of the Pyntacle algorithms; cpu is used to enable fine-grained, multi-threading, parallelism on the enumeration of shortest-paths by relying on just-in-time compilation of Pyntacle's methods by Numba. Finally, gpu is used to defer computationally heavy functions to be executed on CUDA-enabled NVIDIA graphics cards, if available. The value of this enumerator can be passed to the implementation parameter of any key-player methods.
dir(CmodeEnum)
For example, the brute-force search algorithm executed with Octopus can be replicated using the BruteForceSearch method:
from algorithms.bruteforce_search import BruteforceSearch as bfs
bfs.reachability(graph=adv, cmode=CmodeEnum.igraph, metric=KpposEnum.mreach, m=1, k=3)
Please contact us to leave a feedback.